This content has a new home at /learn.
Manipulating NGS data with Galaxy
In this section we will look at practical aspects of manipulation of next-generation sequencing data. We will start with Fastq format produced by most sequencing machines and will finish with SAM/BAM format representing mapped reads.
Set your Galaxy to begin
- If you are new Galaxy → start with the Galaxy 101 tutorial
- Create a new Galaxy history at https://usegalaxy.org (don't forget to log in).
- Import the following four datasets by cutting and pasting these URLs into Galaxy's upload tool (for help see URL upload option in upload tutorial):
https://zenodo.org/record/583613/files/sample1-f.fq.gz
https://zenodo.org/record/583613/files/sample1-r.fq.gz
https://zenodo.org/record/583613/files/sample2-f.fq.gz
https://zenodo.org/record/583613/files/sample2-r.fq.gz
when uploading these dataset set datatype to fastqsanger.gz. The animated image below shows the details of the entire upload process:
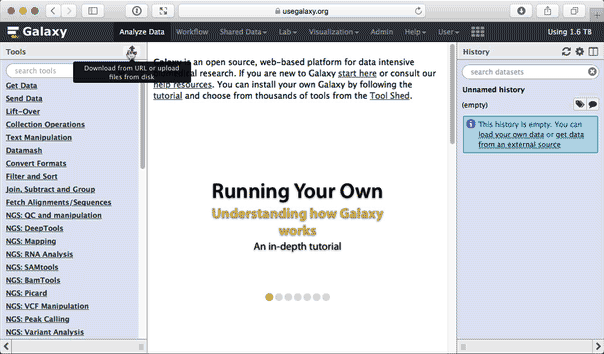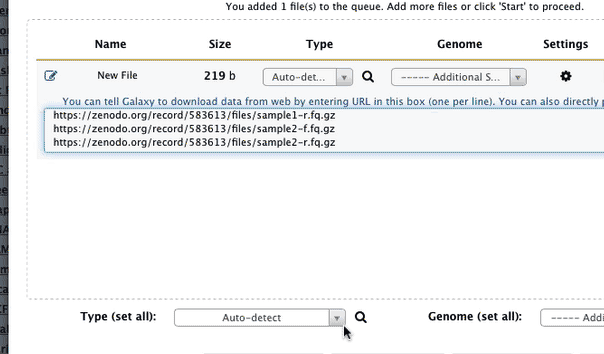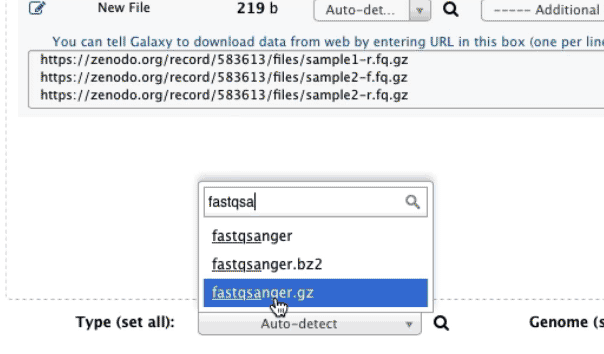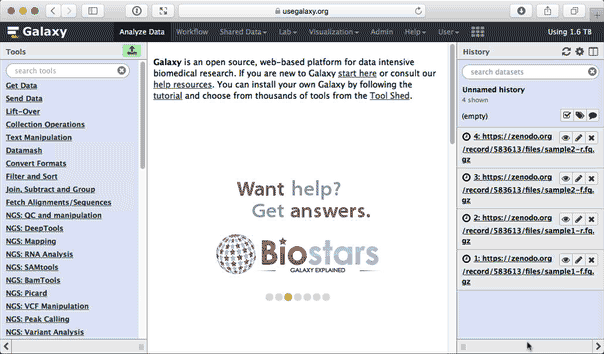 |
Figure 1. Uploading data from URL and setting datatype to fastqsanger.gz (this is a loop, so if you missed something it will repeat itself shortly). |
These are paired end data (datasets with -f is their filename are forward reads and datasets with -r are reverse) representing two independent sampled produced by an Illumina machine.
Upload the datasets. If you've done everything correctly, you will see Galaxy interface looking like this:
 |
| Figure 2. Data are now uploaded. |
Fastq manipulation and quality control
What is Fastq?
FastQ is not a very well defined format. In the beginning various manufacturers of sequencing instruments were free to interpret fastq as they saw fit, resulting in a multitude of fastq flavors. This variation stemmed primarily from different ways of encoding quality values as described here (below you will find explanation of quality scores and their meaning). Today, fastq Sanger version of the format is considered to be the standard form of fastq. Galaxy is using fastq sanger as the only legitimate input for downstream processing tools and provides a number of utilities for converting fastq files into this form (see NGS: QC and manipulation section of Galaxy tools).
Fastq format looks like this:
@M02286:19:000000000-AA549:1:1101:12677:1273 1:N:0:23
CCTACGGGTGGCAGCAGTGAGGAATATTGGTCAATGGACGGAAGTCTGAACCAGCCAAGTAGCGTGCAG
+
ABC8C,:@F:CE8,B-,C,-6-9-C,CE9-CC--C-<-C++,,+;CE<,,CD,CEFC,@E9<FCFCF?9
@M02286:19:000000000-AA549:1:1101:15048:1299 1:N:0:23
CCTACGGGTGGCTGCAGTGAGGAATATTGGACAATGGTCGGAAGACTGATCCAGCCATGCCGCGTGCAG
+
ABC@CC77CFCEG;F9<F89<9--C,CE,--C-6C-,CE:++7:,CF<,CEF,CFGGD8FFCFCFEGCF
@M02286:19:000000000-AA549:1:1101:11116:1322 1:N:0:23
CCTACGGGAGGCAGCAGTAGGGAATCTTCGGCAATGGACGGAAGTCTGACCGAGCAACGCCGCGTGAGT
+
AAC<CCF+@@>CC,C9,F9C9@9-CFFFE@7@:+CC8-C@:7,@EFE,6CF:+8F7EFEEF@EGGGEEE
Each sequencing read is represented by four lines:
@followed by read ID and optional information about sequencing run- sequenced bases
+(optionally followed by the read ID and some additional info)- quality scores for each base of the sequence encoded as ASCII symbols
Paired end data
It is common to prepare pair-end and mate-pair sequencing libraries. This is highly beneficial for a number of applications discussed in subsequent topics. This is because in addition to sequence data we know that forward and reverse reads are physically linked within the sequenced molecule. For now let's just briefly discuss what these are and how they manifest themselves in fastq form.
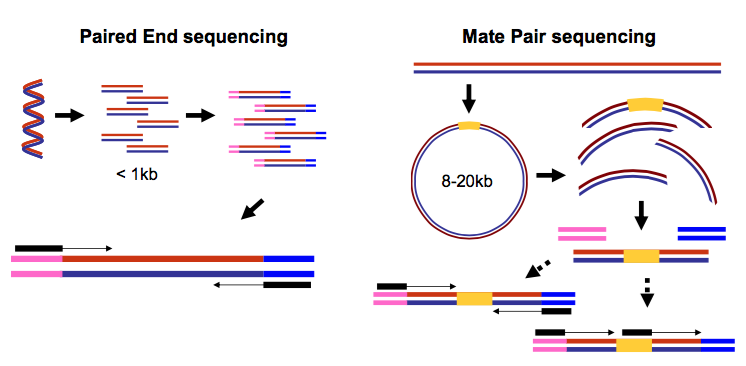 |
| Figure 3. Paired-end and mate-pair reads. In paired end sequencing (left) the actual ends of rather short DNA molecules (less than 1kb) are determined, while for mate pair sequencing (right) the ends of long molecules are joined and prepared in special sequencing libraries. In these mate pair protocols, the ends of long, size-selected molecules are connected with an internal adapter sequence (i.e. linker, yellow) in a circularization reaction. The circular molecule is then processed using restriction enzymes or fragmentation. Fragments are enriched for the linker and outer library adapters are added around the two combined molecule ends. The internal adapter can then be used as a second priming site for an additional sequencing reaction in the same orientation or sequencing can be performed from the second adapter, from the reverse strand. (From Ph.D. dissertation by Martin Kircher) |
Thus in both cases (paired-end and mate-pair) a single physical piece of DNA (or RNA in the case of RNA-seq) is sequenced from two ends and so generates two reads. These can be represented as separate files (two fastq files with first and second reads) or a single file were reads for each end are interleaved. Here are examples:
Two single files
File 1
@M02286:19:000000000-AA549:1:1101:12677:1273 1:N:0:23
CCTACGGGTGGCAGCAGTGAGGAATATTGGTCAATGGACGGAAGTCT
+
ABC8C,:@F:CE8,B-,C,-6-9-C,CE9-CC--C-<-C++,,+;CE
@M02286:19:000000000-AA549:1:1101:15048:1299 1:N:0:23
CCTACGGGTGGCTGCAGTGAGGAATATTGGACAATGGTCGGAAGACT
+
ABC@CC77CFCEG;F9<F89<9--C,CE,--C-6C-,CE:++7:,CF
File 2
@M02286:19:000000000-AA549:1:1101:12677:1273 2:N:0:23
CACTACCCGTGTATCTAATCCTGTTTGATACCCGCACCTTCGAGCTTA
+
--8A,CCE+,,;,<CC,,<CE@,CFD,,C,CFF+@+@CCEF,,,B+C,
@M02286:19:000000000-AA549:1:1101:15048:1299 2:N:0:23
CACTACCGGGGTATCTAATCCTGTTCGCTCCCCACGCTTTCGTCCATC
+
-6AC,EE@::CF7CFF<<FFGGDFFF,@FGGGG?F7FEGGGDEFF>FF
Note that read IDs are identical in two files and they are listed in the same order. In some cases read IDs in the first and second file may be appended with /1 and /2 tags, respectively.
Interleaved file
@1/1
AGGGATGTGTTAGGGTTAGGGTTAGGGTTAGGGTTAGGGTTAGGGTTA
+
EGGEGGGDFGEEEAEECGDEGGFEEGEFGBEEDDECFEFDD@CDD<ED
@1/2
CCTAACCCTAACCCTAACCCTAACCCTAACCCTAACCCTAACCCTAAC
+
GHHHDFDFGFGEGFBGEGGEGEGGGHGFGHFHFHHHHHHHEF?EFEFF
@2/1
AGGGATGTGTTAGGGTTAGGGTTAGGGTTAGGGTTAGGGTTAGGGTTA
+
HHHHHHEGFHEEFEEHEEHHGGEGGGGEFGFGGGGHHHHFBEEEEEFG
@2/2
CCTAACCCTAACCCTAACCCTAACCCTAACCCTAACCCTAACCCTAAC
+
HHHHHHHHHHHHHGHHHHHHGHHHHHHHHHHHFHHHFHHHHHHHHHHH
Here the first and the second reads are identified with /1 and /2 tags (but even without these tags we know that odd reads are in forward orientation and even are in reverse).
Fastq format is not strictly defined and its variations will always cause headache for you. See this page for more information.
What are base qualities?
As we've seen above, fastq datasets contain two types of information:
- sequence of the read
- base qualities for each nucleotide in the read.
The base qualities allow us to judge how trustworthy each base in a sequencing read is. The following excerpt from an excellent tutorial by Friederike Dündar, Luce Skrabanek, Paul Zumbo explains what base qualities are:
Illumina sequencing is based on identifying the individual nucleotides by the fluorescence signal emitted upon their incorporation into the growing sequencing read. Once the fluorescence intensities are extracted and translated into the four letter code. The deduction of nucleotide sequences from the images acquired during sequencing is commonly referred to as base calling. Due to the imperfect nature of the sequencing process and limitations of the optical instruments, base calling will always have inherent uncertainty. This is the reason why FASTQ files store the DNA sequence of each read together with a position-specific quality score that represents the error probability, i.e., how likely it is that an individual base call may be incorrect. The score is called Phred score, Q, which is proportional to the probability p that a base call is incorrect, where 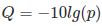 . For example, a Phred score of 10 corresponds to one error in every ten base calls (
. For example, a Phred score of 10 corresponds to one error in every ten base calls (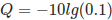 ), or 90% accuracy; a Phred score of 20 corresponds to one error in every 100 base calls, or 99% accuracy. A higher Phred score thus reflects higher confidence in the reported base. To assign each base a unique score identifier (instead of numbers of varying character length), Phred scores are typically represented as ASCII characters. At https://ascii-code.com/ you can see which characters are assigned to what number. For raw reads, the range of scores will depend on the sequencing technology and the base caller used (Illumina, for example, used a tool called Bustard, or, more recently, RTA). Unfortunately, Illumina has been anything but consistent in how they calculated and ASCII-encoded the Phred score (see below)! In addition, Illumina now allows Phred scores for base calls with as high as 45, while 41 used to be the maximum score until the HiSeq X. This may cause issues with downstream applications that expect an upper limit of 41.
), or 90% accuracy; a Phred score of 20 corresponds to one error in every 100 base calls, or 99% accuracy. A higher Phred score thus reflects higher confidence in the reported base. To assign each base a unique score identifier (instead of numbers of varying character length), Phred scores are typically represented as ASCII characters. At https://ascii-code.com/ you can see which characters are assigned to what number. For raw reads, the range of scores will depend on the sequencing technology and the base caller used (Illumina, for example, used a tool called Bustard, or, more recently, RTA). Unfortunately, Illumina has been anything but consistent in how they calculated and ASCII-encoded the Phred score (see below)! In addition, Illumina now allows Phred scores for base calls with as high as 45, while 41 used to be the maximum score until the HiSeq X. This may cause issues with downstream applications that expect an upper limit of 41.
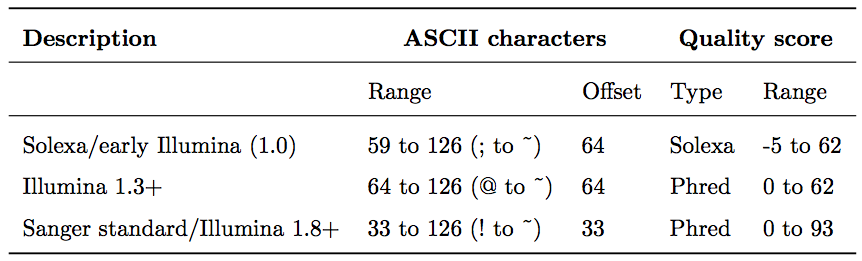
Base call qualities are represented using the Phred score scale. Different Illumina (formerly Solexa) versions used different scores and ASCII offsets. Starting with Illumina format 1.8, the score now represents the standard Sanger/Phred format that is also used by other sequencing platforms and the sequencing archives.
 |
| Figure 4. The ASCII interpretation and ranges of the different Phred score notations used by Illumina and the original Sanger interpretation. Although the Sanger format allows a theoretical score of 93, raw sequencing reads typically do not exceed a Phred score of 60. In fact, most Illumina-based sequencing will result in maximum scores of 41 to 45 (image from Wikipedia). |
Assessing data quality
One of the first steps in the analysis of NGS data is seeing how good the data actually is. FastQC is a fantastic tool allowing you to evaluate the quality of fastq datasets (and deciding whether to blame or not to blame whoever has done sequencing for you).
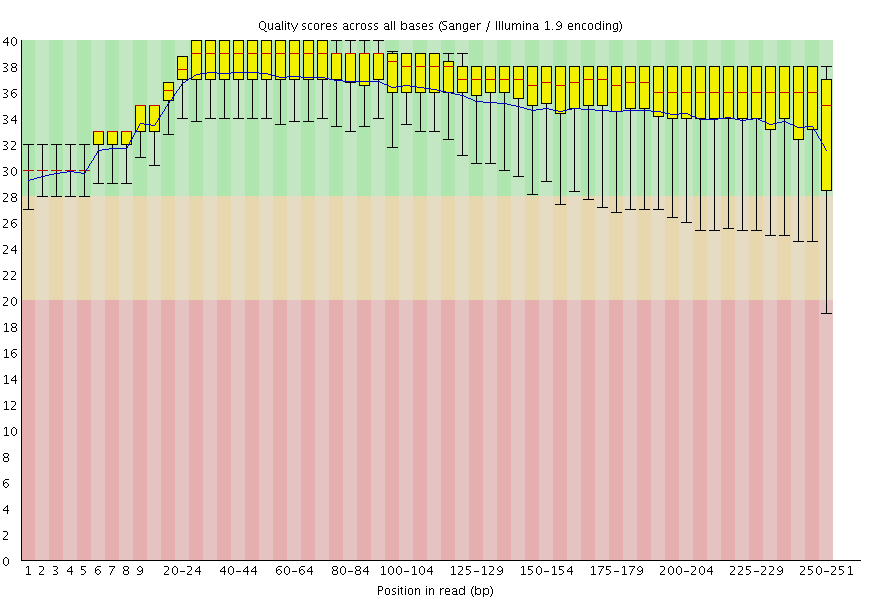 |
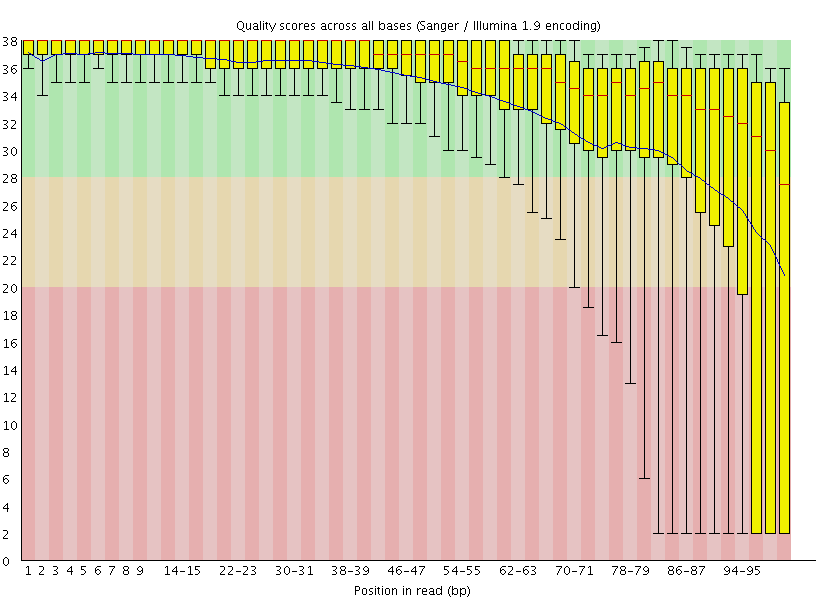 |
| Figure 5. Left: Excellent quality. | Right: Hmmmm....Ok. |
Here you can see FastQC base quality reports (the tools gives you many other types of data) for two datasets: A and B. The A dataset has long reads (250 bp) and very good quality profile with no qualities dropping below phred score of 30. The B dataset is significantly worse with ends of the reads dipping below phred score of 20. The B reads may need to be trimmed for further processing.
It may be challenging to use fastQC when you have a lot of datasets. For example, in our case there are four datasets. FastQC needs to be run on each dataset individually and then one needs to look at each fastQC report individually. This may not be a big problem for four datasets, but it will become an issue if you have 100s or 1,000s of datasets. Phil Ewels has developed a tool called MultiQC that allows to summarize multiple QC reports at once. To run MultiQC you need to run fastQC on individual datasets and then feed fastQC outputs to MultiQC (note that MultiQC is not limited to processing FastQC reports but accepts outputs of many other tools). Galaxy makes this easy as shown in the following video:
In this video we run FastQC on the four datasets and then summarized these data with MultiQC. The following figure shows one of the graphs produced by MultiQC:
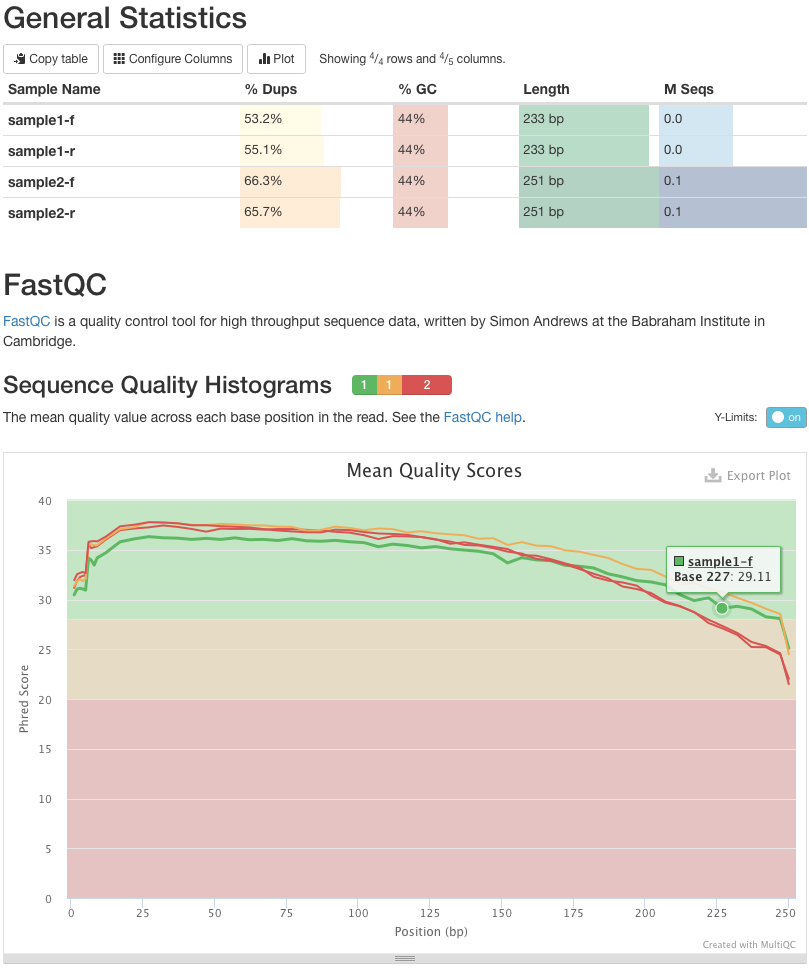 |
Figure 6. A MultiQC report showing quality score distribution for the four sequences using in this tutorial. Here sample1-f has highest quality: its quality scores never dip below phred score of 25. The other datasets are slightly worse, but all are generally acceptable. |
Trimming reads
One of the conclusions from our QC analyses (Fig. 6) is that the quality is acceptable but drops towards the end of the reads (this is typical for Illumina which uses reverse terminators bases with cleave-able color labels. Because the process of cleaving terminators and color labels is not 100% efficient noise accumulates as run progresses and so bases at the ends of reads tend to have lower quality). There is a number of steps we can take to mitigate the effect of low quality bases. One is dynamically trim the reads:
- slide a window across reads
- at every step of the process calculate average quality of bases within the given window
- if quality drops below certain set threshold → stop and trim the read of the read from this point until the end
- output the beginning of the read
One of the tools that performs this procedure is Trimmomatic developed by the Usadel lab. Let's use NGS: QC and manipulation → Trimmomatic to trim out four datasets:
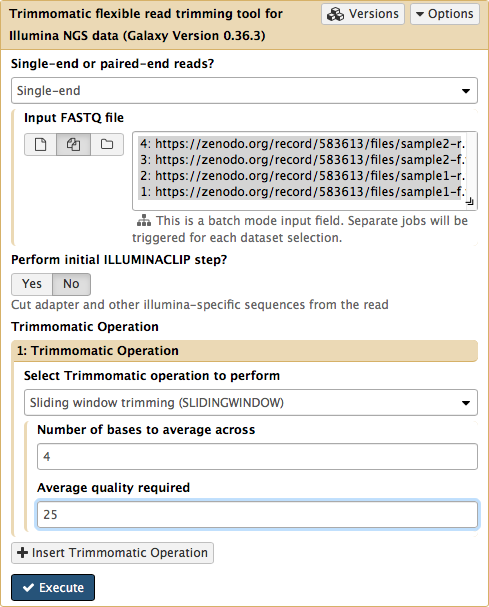 |
| Figure 7. Trimming our datasets with Trimmomatic. Here reads will be trimmed if the base quality averaged across four bases drops below 25. |
To see the effect of trimming on the reads let's take Trimmomatic output, run it through FastQC (NGS: QC and manipulation → FastQCand summarize with MultiQC (NGS: QC and manipulation → multiQC). Below is the quality score distribution graph (the same graph shown in Fig. 6):
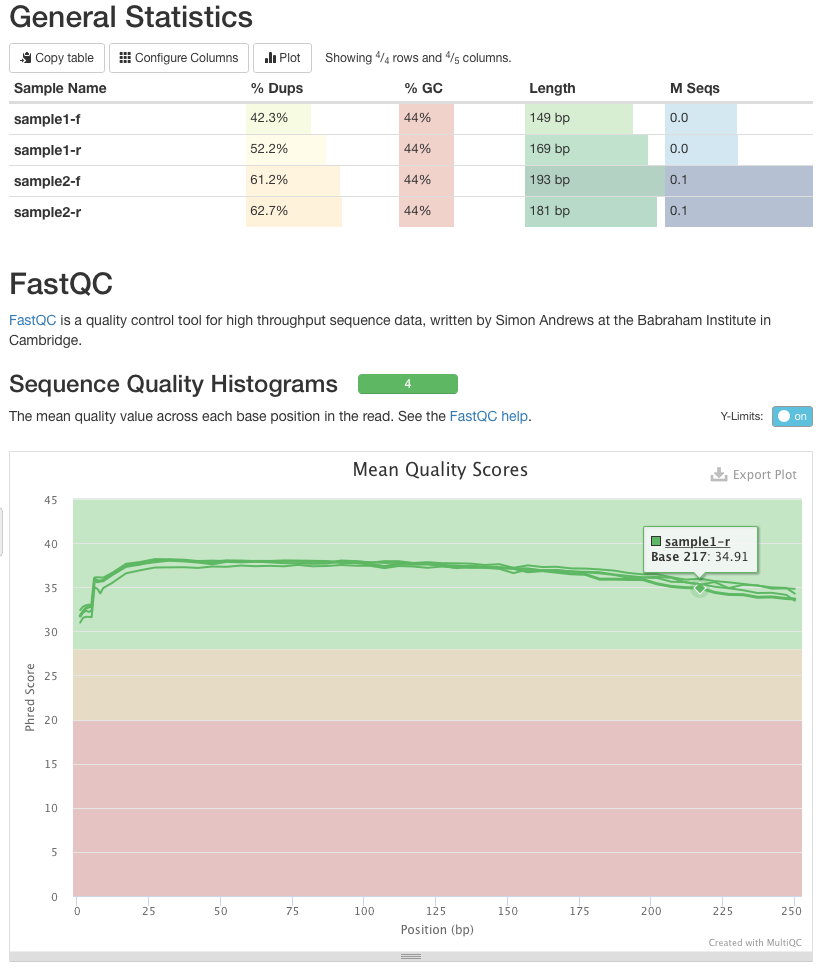 |
| Figure 8. Quality score distribution for trimmed datasets. Compare this image with Fig. 6. You can see that sequences are shorted but quality is significantly higher. |
We will now use trimmed reads as the input to downstream analyses.
Try it yourself
QC, trim, and QC again datasets you have uploaded before to produce a final set of sequences we will be using downstream.
Mapping your data
Mapping of NGS reads against reference sequences is one of the key steps of the analysis. Now it is time to see how this is done in practice. Below is a list of key publications highlighting mainstream mapping tools:
- 2009 Bowtie 1 - Langmead et al.
- 2012 Bowtie 2 - Langmead and Salzberg
- 2009 BWA - Li and Durbin
- 2010 BWA - Li and Durbin
- 2013 BWA-MEM - Li
Mapping against a pre-computed genome index
Mappers usually compare reads against a reference sequence that has been transformed into a highly accessible data structure called genome index. Such indexes should be generated before mapping begins. Galaxy instances typically store indexes for a number of publicly available genome builds.
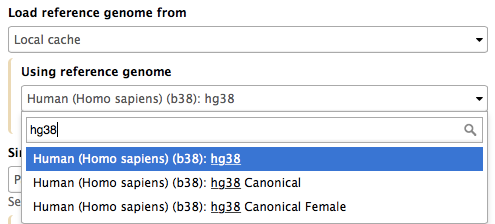 |
| Figure 9. Mapping against a pre-computed index in Galaxy. |
For example, the image above shows indexes for hg38 version of the human genome. You can see that there are actually three choices: (1) hg38, (2) hg38 canonical and (3) hg38 canonical female. The hg38 contains all chromosomes as well as all unplaced contigs. The hg38 canonical does not contain unplaced sequences and only consists of chromosomes 1 through 22, X, Y, and mitochondria. The
hg38 canonical female contains everything from the canonical set with the exception of chromosome Y.
The following video show mapping using BWA-MEM:
Try it yourself
Map datasets uploaded before using BWA against hg38 version of the human genome.
What if pre-computed index does not exist?
If Galaxy does not have a genome you need to map against, you can upload your genome sequence as a FASTA file and use it in the mapper directly as shown below (Load reference genome is set to History).
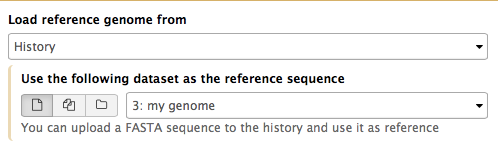 |
| Figure 10. Mapping against a custom index in Galaxy |
In this case Galaxy will first create an index from this dataset and then run mapping analysis against it. The following video shows how this works in practice:
SAM/BAM datasets
The SAM/BAM format is an accepted standard for storing aligned reads (it can also store unaligned reads and some mappers such as BWA are accepting unaligned BAM as input). The binary form of the format (BAM) is compact and can be rapidly searched (if indexed). In Galaxy BAM datasets are always indexed (accompanies by a .bai file) and sorted in coordinate order. In the following discussion I once again rely on tutorial by Friederike Dündar, Luce Skrabanek, and Paul Zumbo.
The Sequence Alignment/Map (SAM) format is a generic nucleotide alignment format that describes the alignment of sequencing reads (or query sequences) to a reference. The human readable, TAB-delimited SAM files can be compressed into the Binary Alignment/Map format. These BAM files are bigger than simply gzipped SAM files, because they have been optimized for fast random access rather than size reduction. Position-sorted BAM files can be indexed so that all reads aligning to a locus can be efficiently retrieved without loading the entire file into memory.
As shown below, SAM files typically contain a header section and an alignment section where each row represents a single read alignment. The following sections will explain the SAM format in a bit more detail. For the most comprehensive and updated information go to https://github.com/samtools/hts-specs.
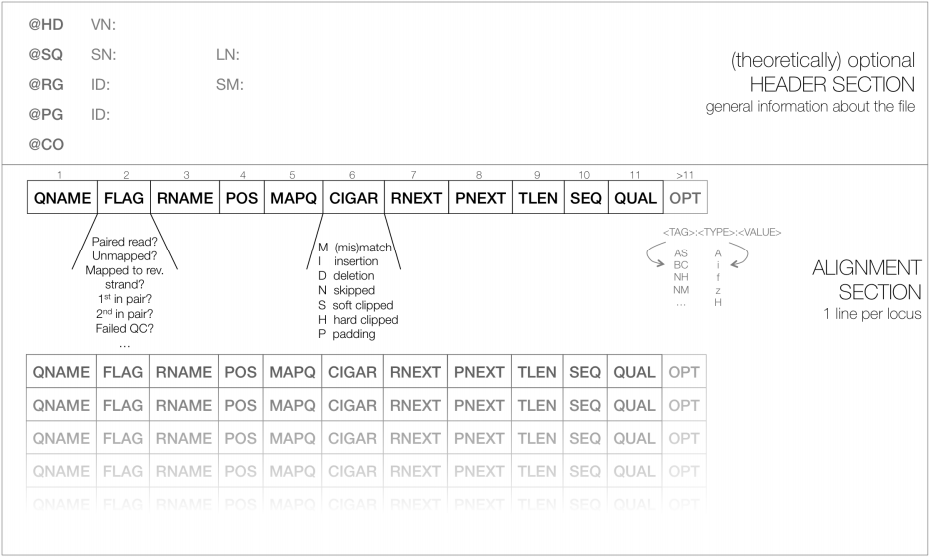 |
| Figure 11. Schematic representation of a SAM file. Each line of the optional header section starts with “@”, followed by the appropriate abbreviation (e.g., SQ for sequence dictionary which lists all chromosomes names (SN) and their lengths (LN)). The vast majority of lines within a SAM file typically correspond to read alignments where each read is described by the 11 mandatory entries (black font) and a variable number of optional fields (grey font; from tutorial by Friederike Dündar, Luce Skrabanek, and Paul Zumbo). |
SAM Header
The header section includes information about how the alignment was generated and stored. All lines in the header section are tab-delimited and begin with the “@” character, followed by tag:value pairs, where tag is a two-letter string that defines the content and the format of value. For example, the “@SQ” line in the header section contains the information about the names and lengths of the *reference sequences to which the reads were aligned. For a hypothetical organism with three chromosomes of length 1,000 bp, the SAM header should contain the following three lines:
@SQ SN:chr1 LN:1000
@SQ SN:chr2 LN:1000
@SQ SN:chr3 LN:1000
SAM alignment section
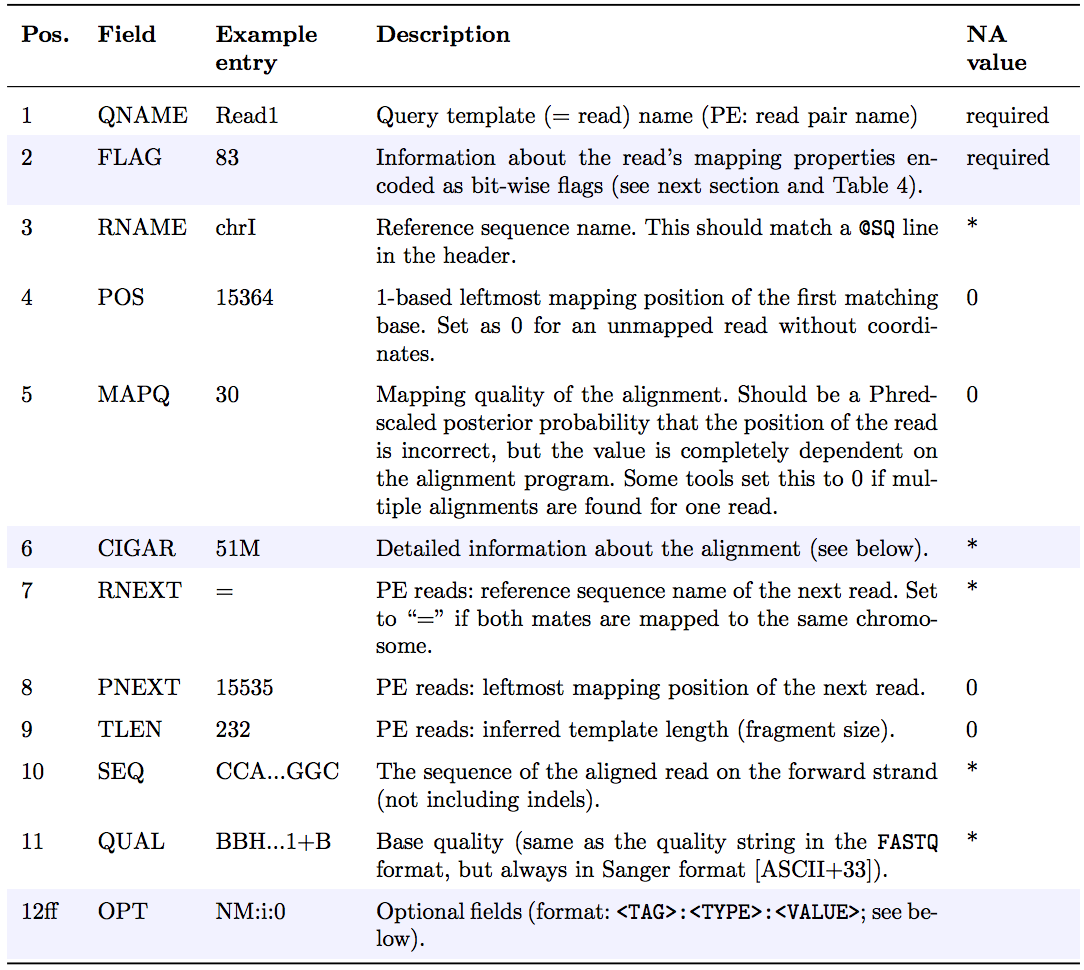
The optional header section is followed by the alignment section where each line corresponds to one sequenced read. For each read, there are 11 mandatory fields that always appear in the same order:
<QNAME> <FLAG> <RNAME> <POS> <MAPQ> <CIGAR> <MRNM> <MPOS> <ISIZE> <SEQ> <QUAL>
If the corresponding information is unavailable or irrelevant, field values can be ‘0’ or ‘*’ (depending on the field, see below), but they cannot be missing! After the 11 mandatory fields, a variable number of optional fields can be present. Here’s an example of one single line of a real-life SAM file (you may need to scroll sideways):
ERR458493 .552967 16 chrI 140 255 12 M61232N37M2S * 0 0 CCACTCGTTCACCAGGGCCGGCGGGCTGATCACTTTATCGTGCATCTTGGC BB?HHJJIGHHJIGIIJJIJGIJIJJIIIGHBJJJJJJHHHHFFDDDA1+B NH:i:1 HI:i:1 AS:i:41 nM:i:2
The following table explains the format and content of each field. The FLAG, CIGAR, and the optional fields (marked in blue) are explained in more detail below. The number of optional fields can vary widely between different SAM files and even between reads within in the same file. The field types marked in blue are explained in more detail in the main text below.
FLAG field
The FLAG field encodes various pieces of information about the individual read, which is particularly important for PE reads. It contains an integer that is generated from a sequence of Boolean bits (0, 1). This way, answers to multiple binary (Yes/No) questions can be compactly stored as a series of bits, where each of the single bits can be addressed and assigned separately.
The following table gives an overview of the different properties that can be encoded in the FLAG field. The developers of the SAM format and samtools tend to use the hexadecimal encoding as a means to refer to the different bits in their documentation. The value of the FLAG field in a given SAM file, however, will always be the decimal representation of the sum of the underlying binary values (as shown in Table below, row 2).
 |
Figure 12. The FLAG field of SAM files stores information about the respective read alignment in one single decimal number. The decimal number is the sum of all the answers to the Yes/No questions associated with each binary bit. The hexadecimal representation is used to refer to the individual bits (questions). A bit is set if the corresponding state is true. For example, if a read is paired, 0x1 will be set, returning the decimal value of 1. Therefore, all FLAG values associated with paired reads must be uneven decimal numbers. Conversely, if the 0x1 bit is unset (= read is not paired), no assumptions can be made about 0x2, 0x8, 0x20, 0x40 and 0x80 because they refer to paired reads (from tutorial by Friederike Dündar, Luce Skrabanek, and Paul Zumbo). |
In a run with single reads, the flags you most commonly see are:
- 0: This read has been mapped to the forward strand. (None of the bit-wise flags have been set.)
- 4: The read is unmapped (
0x4is set). - 16: The read is mapped to the reverse strand (
0x10is set)
(0x100, 0x200 and 0x400 are not used by most aligners/mappers, but could, in principle be set for single reads.) Some common FLAG values that you may see in a PE experiment include:
| FLAG value | Meaning |
|---|---|
| 69 (= 1 + 4 + 64) | The read is paired, is the first read in the pair, and is unmapped. |
| 77 (= 1 + 4 + 8 + 64) | The read is paired, is the first read in the pair, both are unmapped. |
| 83 (= 1 + 2 + 16 + 64) | The read is paired, mapped in a proper pair, is the first read in the pair, and it is mapped to the reverse strand. |
| 99 (= 1 + 2 + 32 + 64) | The read is paired, mapped in a proper pair, is the first read in the pair, and its mate is mapped to the reverse strand. |
| 133 (= 1 + 4 + 128) | The read is paired, is the second read in the pair, and it is unmapped. |
| 137 (= 1 + 8 + 128) | The read is paired, is the second read in the pair, and it is mapped while its mate is not. |
| 141 (= 1 + 4 + 8 + 128) | The read is paired, is the second read in the pair, but both are unmapped. |
| 147 (= 1 + 2 + 16 + 128) | The read is paired, mapped in a proper pair, is the second read in the pair, and mapped to the reverse strand. |
| 163 (= 1 + 2 + 32 + 128) | The read is paired, mapped in a proper pair, is the second read in the pair, and its mate is mapped to the reverse strand. |
A useful website for quickly translating the FLAG integers into plain English explanations like the ones shown above is: https://broadinstitute.github.io/picard/explain-flags.html
CIGAR string
CIGAR stands for Concise Idiosyncratic Gapped Alignment Report. This sixth field of a SAM file
contains a so-called CIGAR string indicating which operations were necessary to map the read to the reference sequence at that particular locus.
The following operations are defined in CIGAR format (also see figure below):
- M - Alignment (can be a sequence match or mismatch!)
- I - Insertion in the read compared to the reference
- D - Deletion in the read compared to the reference
- N - Skipped region from the reference. For mRNA-to-genome alignments, an N operation represents an intron. For other types of alignments, the interpretation of N is not defined.
- S - Soft clipping (clipped sequences are present in read); S may only have H operations between them and the ends of the string
- H - Hard clipping (clipped sequences are NOT present in the alignment record); can only be present as the first and/or last operation
- P - Padding (silent deletion from padded reference)
- = - Sequence match (not widely used)
- X - Sequence mismatch (not widely used)
The sum of lengths of the M, I, S, =, X operations must equal the length of the read. Here are some examples:
 |
| Figure 13. Examples of CIGAR strings (from tutorial by Friederike Dündar, Luce Skrabanek, and Paul Zumbo). |
Optional fields
Following the eleven mandatory SAM file fields, the optional fields are presented as key-value
pairs in the format of <TAG>:<TYPE>:<VALUE>, where TYPE is one of:
A- Characteri- Integerf- Float numberZ- StringH- Hex string
The information stored in these optional fields will vary widely depending on the mapper and new tags can be added freely. In addition, reads within the same SAM file may have different numbers of optional fields, depending on the program that generated the SAM file. Commonly used optional tags include:
AS:i- Alignment scoreBC:Z- Barcode sequenceHI:i- Match is i-th hit to the readNH:i- Number of reported alignments for the query sequenceNM:i- Edit distance of the query to the referenceMD:Z- String that contains the exact positions of mismatches (should complement the CIGAR string)RG:Z- Read group (should match the entry after ID if @RG is present in the header.
Thus, for example, we can use the NM:i:0 tag to select only those reads which map perfectly to the reference(i.e., have no mismatches). While the optional fields listed above are fairly standardized, tags that begin with X, Y, and Z are reserved for particularly free usage and will never be part of the official SAM file format specifications. XS, for example, is used by TopHat (an RNA-seq analysis tool we will discuss later) to encode the strand information (e.g., XS:A:+) while Bowtie2 and BWA use XS:i: for reads with multiple alignments to store the alignment score for the next-best-scoring alignment (e.g., XS:i:30).
Read Groups
One of the key features of SAM/BAM format is the ability to label individual reads with readgroup tags. This allows pooling results of multiple experiments into a single BAM dataset. This significantly simplifies downstream logistics: instead of dealing with multiple datasets one can handle just one. Many downstream analysis tools such as variant callers are designed to recognize readgroup data and output results on per-readgroup basis.
One of the best descriptions of BAM readgroups is on GATK support site. We have gratefully stolen two tables describing the most important readgroup tags - ID, SM, LB, and PL - from GATK forum and provide them here:

GATK forum also provides the following example:

To see an example of read group manipulation in Galaxy see the following video. In this video we use two BAM datasets as an example. We add readgroups and shown how it changes the underling BAM (SAM) data:
Effects of PCR duplicates
Preparation of sequencing libraries (at least at the time of writing) for technologies such as Illumina involves PCR amplification. It is required to generate sufficient number of sequencing templates so that a reliable detection can be performed by base callers. Yet PCR has it's biases, which are especially profound in cases of multitemplate PCR used for construction of sequencing libraries (Kanagawa et al. 2003).
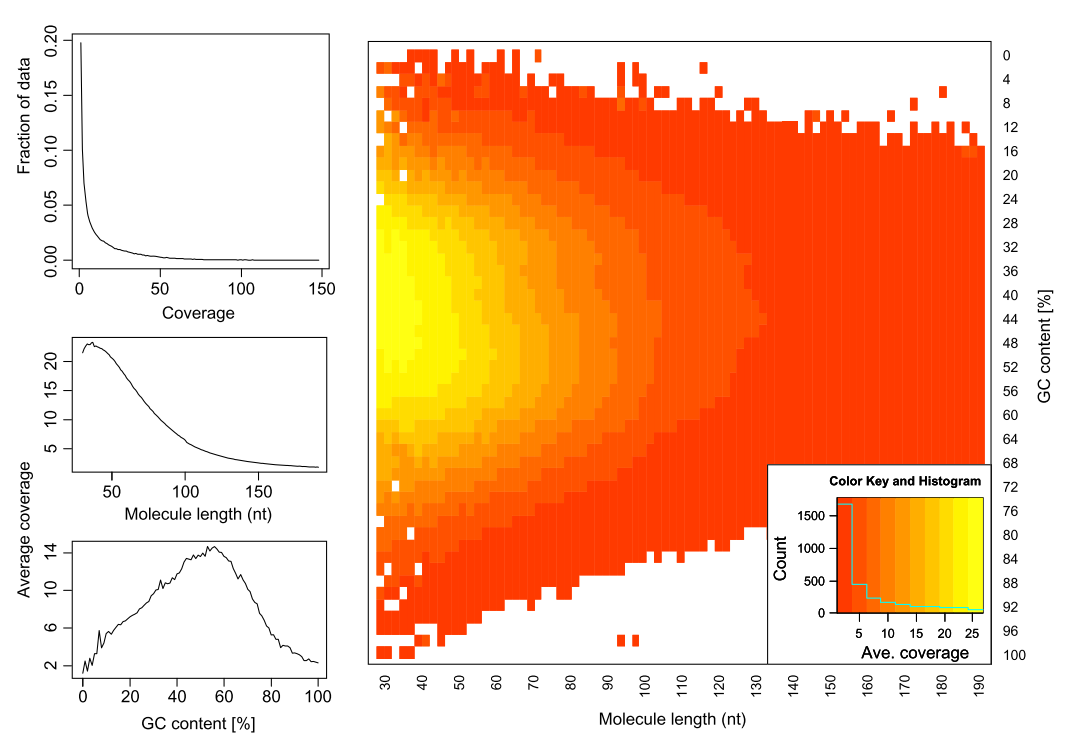 |
| Figure 14. Analyzing molecules aligning with the same outer coordinates, a mapping quality of at least 30 and a length of at least 30nt, resulted in an average coverage of 12.9 per PCR duplicate and an empirical coverage distribution similar to an exponential/power law distribution (left upper panel). This indicates that many molecules are only observed for deeper sequencing while other molecules are available at higher frequencies. Analyzing length (left middle panel) and GC content (left lower panel) patterns as well as the combination (right panel) shows higher PCR duplicate counts for a GC content between 30% to 70% as well as for shorter molecules compared to longer molecules. This effect may be due to an amplification bias from the polymerase or the cluster generation process necessary for Illumina sequencing. From Ph.D. dissertation of Martin Kircher). |
Duplicates can be identified based on their outer alignment coordinates or using sequence-based clustering. One of the common ways for identification of duplicate reads is the MarkDuplicates utility from Picard package. It is designed to identify both PCR and optical duplicates:
Duplicates are identified as read pairs having identical 5' positions (coordinate and strand) for both reads in a mate pair (and optionally, matching unique molecular identifier reads; see BARCODE_TAG option). Optical, or more broadly Sequencing, duplicates are duplicates that appear clustered together spatially during sequencing and can arise from optical/imagine-processing artifacts or from bio-chemical processes during clonal amplification and sequencing; they are identified using the READ_NAME_REGEX and the OPTICAL_DUPLICATE_PIXEL_DISTANCE options. The tool's main output is a new SAM or BAM file in which duplicates have been identified in the SAM flags field, or optionally removed (see REMOVE_DUPLICATE and REMOVE_SEQUENCING_DUPLICATES), and optionally marked with a duplicate type in the 'DT' optional attribute. In addition, it also outputs a metrics file containing the numbers of READ_PAIRS_EXAMINED, UNMAPPED_READS, UNPAIRED_READS, UNPAIRED_READ DUPLICATES, READ_PAIR_DUPLICATES, and READ_PAIR_OPTICAL_DUPLICATES. Usage example: java -jar picard.jar MarkDuplicates I=input.bam \ O=marked_duplicates.bam M=marked_dup_metrics.txt.
Sampling coincidence duplicates
However, one has to be careful when removing duplicates in cases when the sequencing targets are small (e.g., sequencing of bacterial, viral, or organellar genomes as well as amplicons). This is because when sequencing target is small reads will have the same coordinates by chance and not because of PCR amplification issues. The figure below illustrates the fine balance between estimates allele frequency, coverage, and variation in insert size:
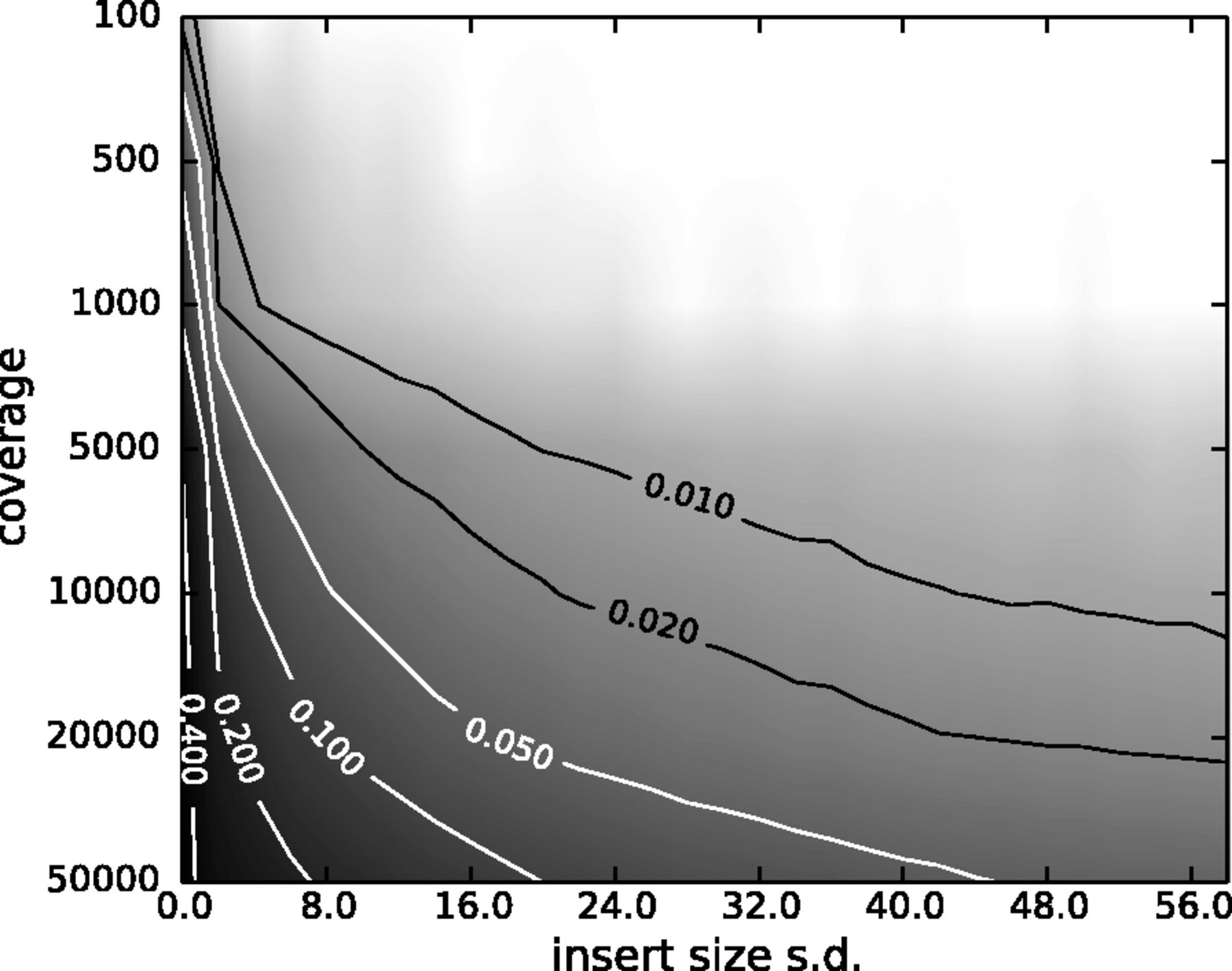 |
| Figure 15. The Variant Allele Frequency (VAF) bias determined by coverage and insert size variance. Reads are paired-end and read length is 76. The insert size distribution is modeled as a Gaussian distribution with mean at 200 and standard deviation shown on the x-axis. The true VAF is 0.05. The darkness at each position indicates the magnitude of the bias in the VAF. (From Zhou et al. 2013). |
Putting it all together
In Galaxy we support four major toolsets for processing of SAM/BAM datasets:
- DeepTools - a suite of user-friendly tools for the visualization, quality control and normalization of data from deep-sequencing DNA sequencing experiments.
- SAMtools - various utilities for manipulating alignments in the SAM/BAM format, including sorting, merging, indexing and generating alignments in a per-position format.
- BAMtools - a toolkit for reading, writing, and manipulating BAM (genome alignment) files.
- Picard - a set of Java tools for manipulating high-throughput sequencing data (HTS) data and formats.
The following two videos highlight major steps of fastq-to-BAM analysis trajectory.
Organizing and QC'ing multiple datasets
In a typical analysis scenario a user usually processes multiple datasets. To make the two following videos representative of real-live analyses we use a set of four samples, each consisting of two forward and reverse sets of reads for a total of eight fastq datasets. The first video describes upload, QC, and preparation of these datasets for the subsequent analysis. The figure below outlines steps highlighted in the video:
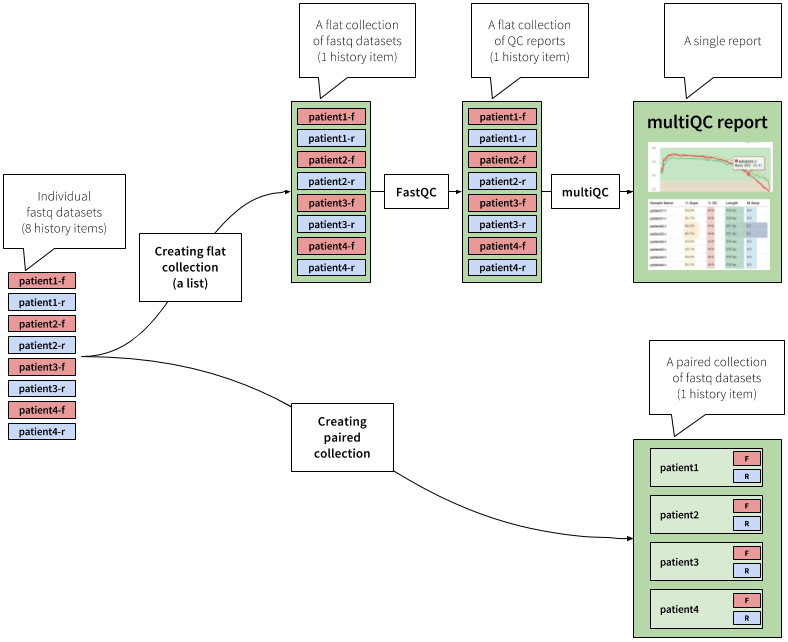 |
Figure 16. The analysis shown in this figure and the following video begins with uploading of 8 datasets into history. These datasets are first combined into a flat collection - a single entity containing eight fastq datasets. This collection is then analyzed with fastQC tool. This analyses produces another collection containing 8 fastQC outputs. Because it is inconvenient to look at individual fastQC reports, we feed the entire collection to multiQC tool, which produces a single summary outputs aggregating data from 8 fastQC reports. At this point we are happy with the quality of the data and ready to move on with the subsequent analysis. To do this we organize our datasets into a different type of collection - a paired collection. You can see that the paired collection is "deeper" that a flat collection: it contains samples and for each sample is lists corresponding sets of forward and reverse reads (shown and red and blue boxes with "F" and "R"). To learn more about collections see this tutorial. |
After QC'ing we move on to map the reads, process the resulting BAM datasets, and visualize coverage in a genome browser. The following figure and video detail these steps:
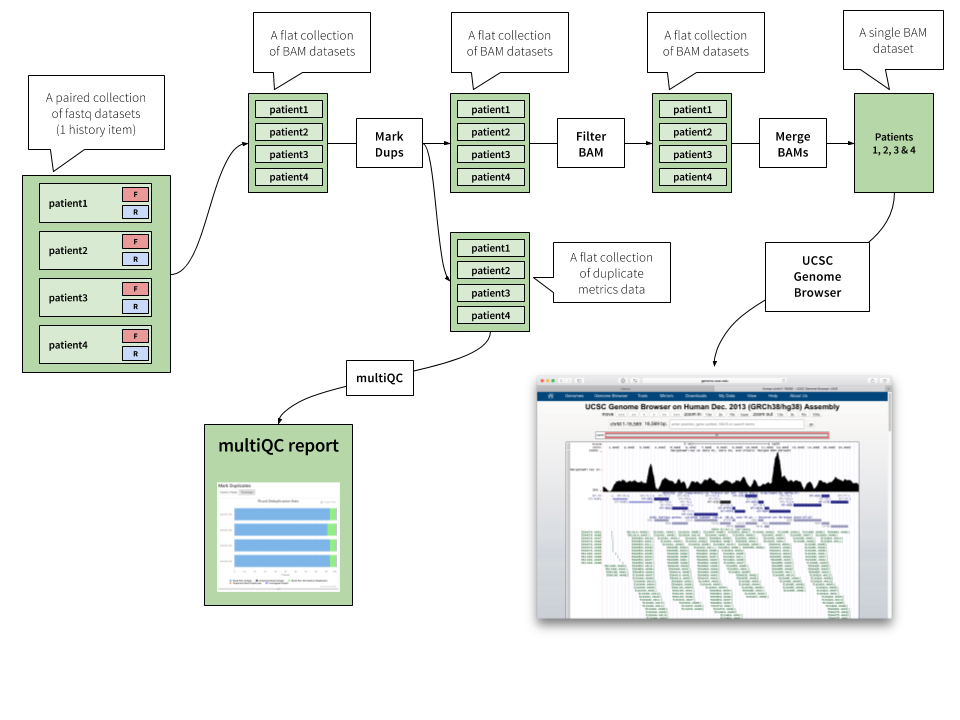 |
Figure 17. In this analysis (see video below) we begin with a paired collection of fastq datasets. Mapping this collection to human genome with bwa mem produces a flat collection of BAM datasets. (EXTREMELY IMPORTANT: when mapping with bwa mem we set readgroups (at time marker 00:40 in the video). This allows us to merge individual BAM datasets into one at the end of this analysis.) Next using Picard's MarkDuplicates tool we process output of bwa mem. This step produces two collections: (1) a collection of deduplicated BAMs and (2) a collection of duplicate metrics data produced by MarkDuplicates tool. We use multiQC to visualize the duplicate metrics. We then filter BAM collection produced by MarkDuplicates using Filter SAM or BAM tool to retain only properly mapped reads with mapping quality above 20 and mapping only to mitochondria (chrM). Finally output of the filtering step is merged with MergeSAM tool and displayed in the UCSC Genome Browser. Again, merging is only possible because we have set the readgroups during the mapping step. |
The merged BAM file can be using in a variety of downstream analyses. In this example we only used four samples represented by eight paired fastq datasets. Collection, prominently featured in this tutorial, make it easy to apply the same exact analysis logic to 100s or 1,000s of datasets.
Try it yourself
Perform a similar analyses with your own data.
If things don't work...
- ...create an issue by clicking "New issue" button here
- ...complain. Use Galaxy's support forum to do this.